The Healthy AI Lab at Chalmers University of Technology conducts academic research into machine learning and artificial intelligence motivated by challenges in healthcare: causality, decision-making and clinical applications. The lab is led by Fredrik Johansson.
-
Expanding the Action Space of LLMs to Reason Beyond Language
NeurIPS 2025 Math-AI Workshop [Paper URL]Large Language Models (LLMs) are powerful reasoners in natural language, but their actions are typically confined to outputting vocabulary tokens. As a result, interactions with external environments—such as symbolic operators or simulators—must be expressed through text in predefined formats, parsed, and routed to external interfaces. This overloads the model’s language with both reasoning and control duties, and requires a hand-crafted parser, external to the LLM. To address this, we decouple environment interactions from language by internalizing them in an Expanded Action space (ExpA), beyond the vocabulary. The model starts reasoning in the default language environment, but may trigger routing actions and switch to an external environment at any time. From there, the model can only invoke environment-specific actions, receive feedback from the environment, and potentially route back to language as a result. To promote effective exploration of the expanded action space and new environments, we introduce ExpA Reinforcement Learning (EARL) with counterfactual policy optimization. On tasks requiring multi-turn interactions and contingent planning, EARL outperforms strong baselines with vocabulary-constrained actions. It performs robustly across calculator-based multi-task learning and, in the partially observed sorting problem, achieves perfect Sort-4 accuracy while self-discovering an efficient algorithm competitive with classical designs.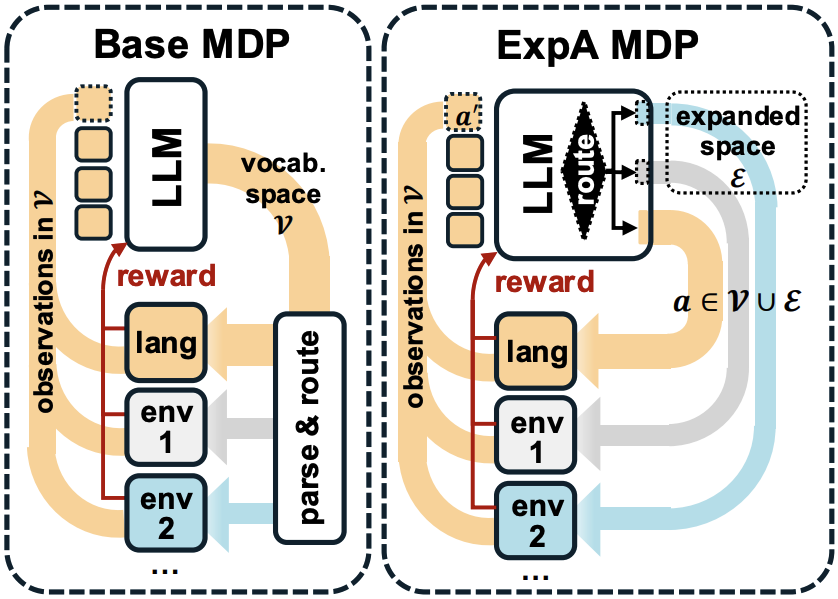
Oct 7, 2025
-
Latent Preference Bandits
TBD [Paper URL]Bandit algorithms are guaranteed to solve diverse sequential decision-making problems, provided that a sufficient exploration budget is available. However, learning from scratch is often too costly for personalization tasks where a single individual faces only a small number of decision points. Latent bandits offer substantially reduced exploration times for such problems, given that the joint distribution of a latent state and the rewards of actions is known and accurate. In practice, finding such a model is non-trivial, and there may not exist a small number of latent states that explain the responses of all individuals. For example, patients with similar latent conditions may have the same preference in treatments but rate their symptoms on different scales. With this in mind, we propose relaxing the assumptions of latent bandits to require only a model of the \emph{preference ordering} of actions in each latent state. This allows problem instances with the same latent state to vary in their reward distributions, as long as their preference orderings are equal. We give a posterior-sampling algorithm for this problem and demonstrate that its empirical performance is competitive with latent bandits that have full knowledge of the reward distribution when this is well-specified, and outperforms them when reward scales differ between instances with the same latent state.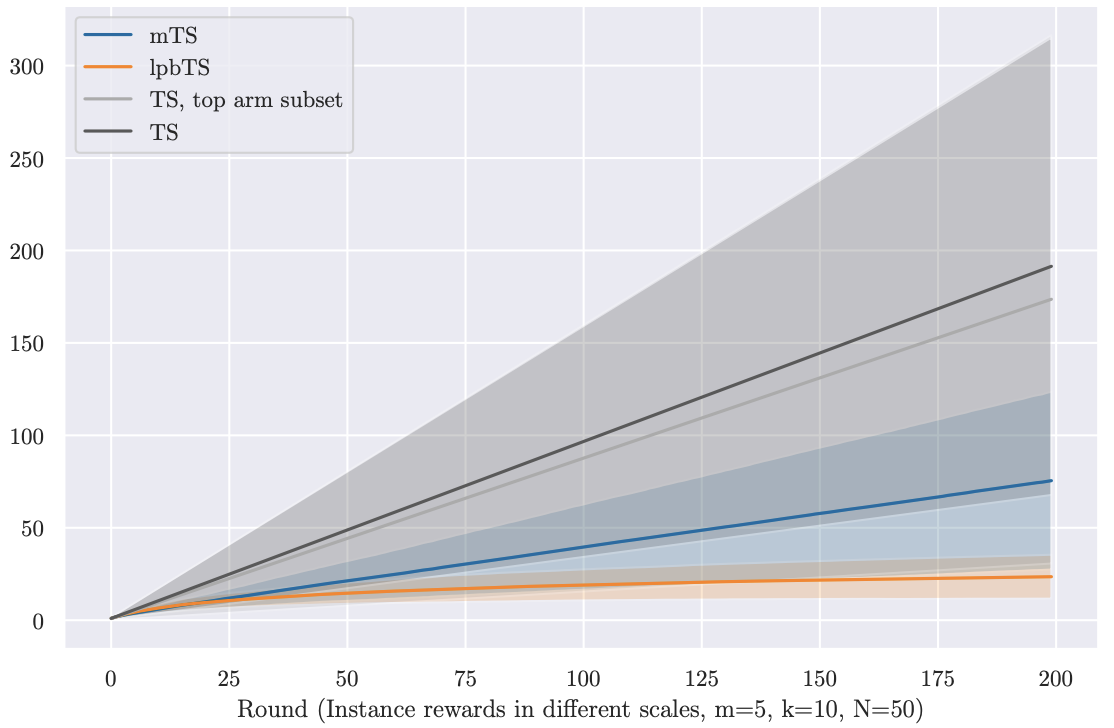
Aug 7, 2025
-
Prediction Models That Learn to Avoid Missing Values
ICML 2025 (spotlight) [Paper URL]Handling missing values at test time is challenging for machine learning models, especially when aiming for both high accuracy and interpretability. Established approaches often add bias through imputation or excessive model complexity via missingness indicators. Moreover, either method can obscure interpretability, making it harder to understand how the model utilizes the observed variables in predictions. We propose missingness-avoiding (MA) machine learning, a general framework for training models to rarely require the values of missing (or imputed) features at test time. We create tailored MA learning algorithms for decision trees, tree ensembles, and sparse linear models by incorporating classifier-specific regularization terms in their learning objectives. The tree-based models leverage contextual missingness by reducing reliance on missing values based on the observed context. Experiments on real-world datasets demonstrate that MA-DT, MA-LASSO, MA-RF, and MA-GBT effectively reduce the reliance on features with missing values while maintaining predictive performance competitive with their unregularized counterparts. This shows that our framework gives practitioners a powerful tool to maintain interpretability in predictions with test-time missing values.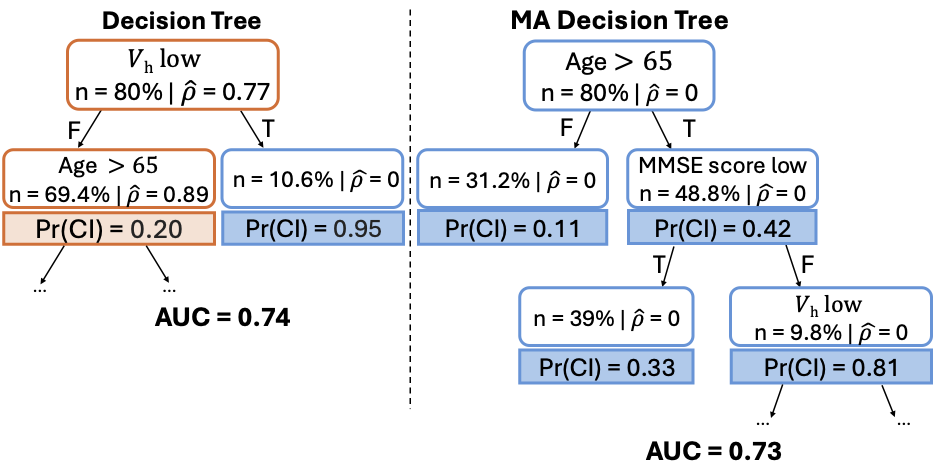
Jul 29, 2025
-
Representing History for Interpretable Policy Modeling
Machine Learning for Health (ML4H) 2024 [Paper URL]Modeling policies for sequential clinical decision-making based on observational data is useful for describing treatment practices, standardizing frequent patterns in treatment, and evaluating alternative policies. For each task, it is essential that the policy model is interpretable. Learning accurate models requires effectively capturing a patient’s state, either through sequence representation learning or carefully crafted summaries of their medical history. While recent work has favored the former, it remains a question as to how histories should best be represented for interpretable policy modeling. Focused on model fit, we systematically compare diverse approaches to summarizing patient history for interpretable modeling of clinical policies across four sequential decision-making tasks. We illustrate differences in the policies learned using various representations by breaking down evaluations by patient subgroups, critical states, and stages of treatment, highlighting challenges specific to common use cases. We find that interpretable sequence models using learned representations perform on par with black-box models across all tasks. Interpretable models using hand-crafted representations perform substantially worse when ignoring history entirely, but are made competitive by incorporating only a few aggregated and recent elements of patient history. The added benefits of using a richer representation are pronounced for subgroups and in specific use cases. This underscores the importance of evaluating policy models in the context of their intended use.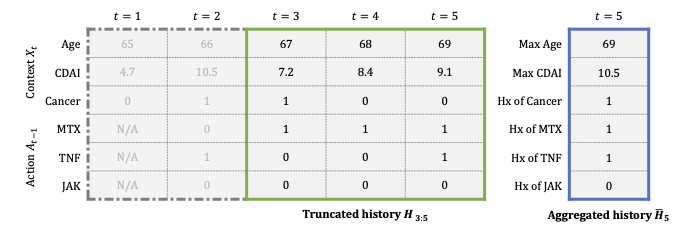
Jul 29, 2025
-
Expert Study on Interpretable Machine Learning Models with Missing Values
Machine Learning for Health (ML4H) 2024 Findings [Paper URL]Inherently interpretable machine learning (IML) models offer valuable support for clinical decision-making but face challenges when features contain missing values. Traditional approaches, such as imputation or discarding incomplete records, are often impractical in scenarios where data is missing at test time. We surveyed 55 clinicians from 29 French trauma centers, collecting 20 complete responses to study their interaction with three IML models in a real-world clinical setting for predicting hemorrhagic shock with missing values. Our findings reveal that while clinicians recognize the value of interpretability and are familiar with common IML approaches, traditional imputation techniques often conflict with their intuition. Instead of imputing unobserved values, they rely on observed features combined with medical intuition and experience. As a result, methods that natively handle missing values are preferred. These findings underscore the need to integrate clinical reasoning into future IML models to enhance human-computer interaction.
Mar 1, 2025
-
Applying Machine Learning to High-Dimensional Proteomics Datasets for the Identification of Alzheimer’s Disease Biomarkers
Fluids and Barriers of the CNS [Paper URL]This study explores the application of machine learning to high-dimensional proteomics datasets for identifying Alzheimer's disease (AD) biomarkers. AD, a neurodegenerative disorder affecting millions worldwide, necessitates early and accurate diagnosis for effective management. We leverage Tandem Mass Tag (TMT) proteomics data from the cerebrospinal fluid (CSF) samples from the frontal cortex of patients with idiopathic normal pressure hydrocephalus (iNPH), a condition often comorbid with AD, with rare access to both lumbar and ventricular samples. Our methodology includes extensive data preprocessing to address batch effects and missing values, followed by the use of the Synthetic Minority Over-sampling Technique (SMOTE) for data augmentation to overcome the small sample size. We apply linear, and non-linear machine learning models, and ensemble methods, to compare iNPH patients with and without biomarker evidence of AD pathology (Aβ−T− or Aβ+T+) in a classification task. We present a machine learning workflow for working with high-dimensional TMT proteomics data that addresses their inherent data characteristics. Our results demonstrate that batch effect correction has no or minor impact on the models' performance and robust feature selection is critical for model stability and performance, especially in the high-dimensional proteomics data setting for AD diagnostics. The results further indicated that removing features with missing values produced stronger models than imputing them, and the batch effect had minimal impact on the models Our best-performing disease-progression detection model, a random forest, achieves an AUC of 0.84 ($\pm$ 0.03). We identify several novel protein biomarkers candidates, such as FABP3 and GOT1, with potential diagnostic value for AD pathology detection, suggesting the necessity of different biomarkers for AD diagnoses for patients with iNPH, and considering different biomarkers for ventricular and lumbar CSF samples. This work underscores the importance of a meticulous machine learning process in enhancing biomarker discovery. Our study also provides insights in translating biomarkers from other central nervous system diseases like iNPH, and both ventricular and lumbar CSF samples for biomarker discovery, providing a foundation for future research and clinical applications.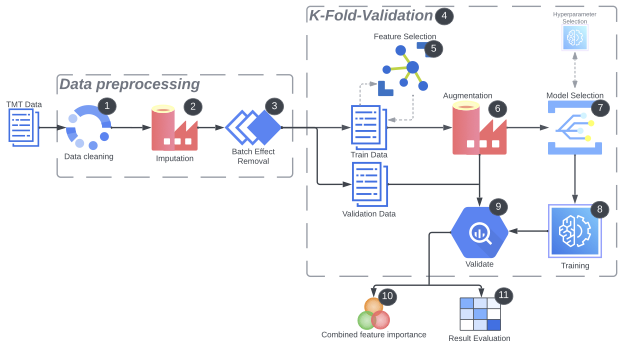
Feb 28, 2025
-
IncomeSCM: From tabular data set to time-series simulator and causal estimation benchmark
NeurIPS 2024 (To appear) [Paper URL]Evaluating observational estimators of causal effects demands information that is rarely available: unconfounded interventions and outcomes from the population of interest, created either by randomization or adjustment. As a result, it is customary to fall back on simulators when creating benchmark tasks. Simulators offer great control but are often too simplistic to make challenging tasks, either because they are hand-designed and lack the nuances of real-world data, or because they are fit to observational data without structural constraints. In this work, we propose a general, repeatable strategy for turning observational data into sequential structural causal models and challenging estimation tasks by following two simple principles: 1) fitting real-world data where possible, and 2) creating complexity by composing simple, hand-designed mechanisms. We implement these ideas in a highly configurable software package and apply it to the well-known Adult income data set to construct the \tt IncomeSCM simulator. From this, we devise multiple estimation tasks and sample data sets to compare established estimators of causal effects. The tasks present a suitable challenge, with effect estimates varying greatly in quality between methods, despite similar performance in the modeling of factual outcomes, highlighting the need for dedicated causal estimators and model selection criteria.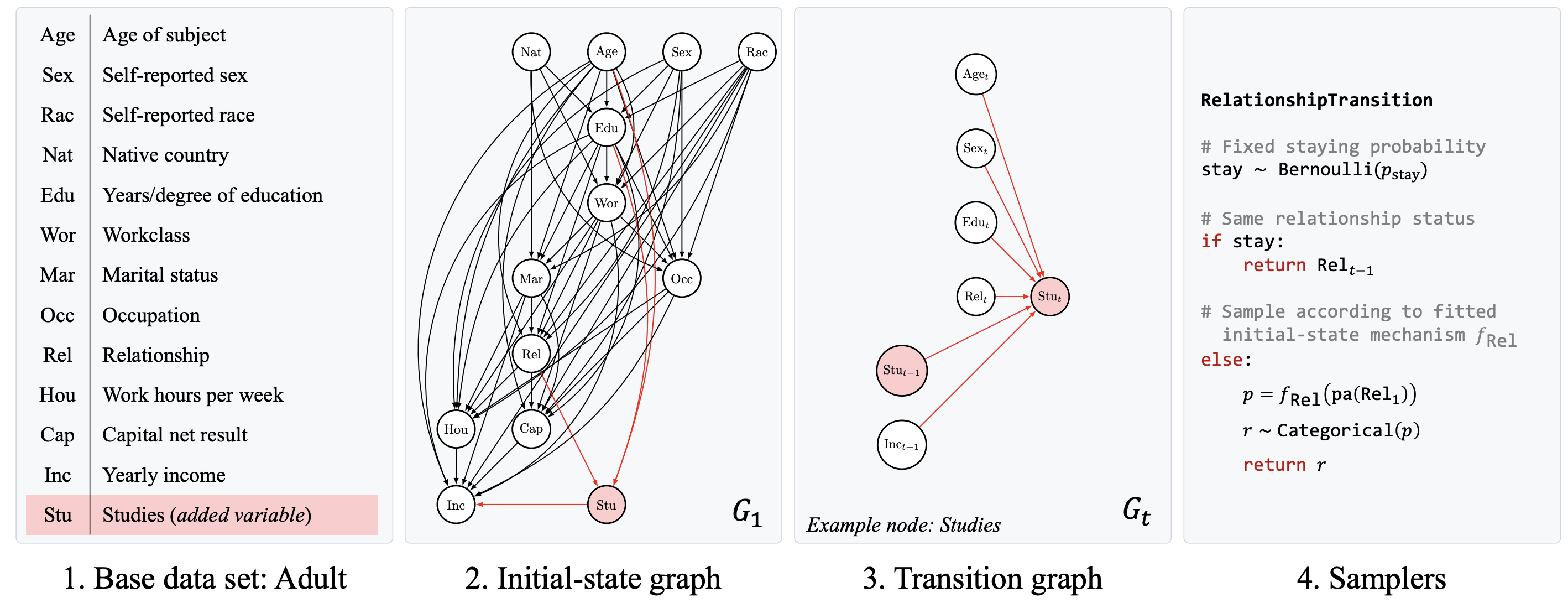
Sep 29, 2024
-
Active Preference Learning for Ordering Items In- and Out-of-Sample
NeurIPS 2024 [Paper URL]Learning an ordering of items based on pairwise comparisons is useful when items are difficult to rate consistently on an absolute scale, for example, when annotators have to make subjective assessments. When exhaustive comparison is infeasible, actively sampling item pairs can reduce the number of annotations necessary for learning an accurate ordering. However, many algorithms ignore shared structure between items, limiting their sample efficiency and precluding generalization to new items. It is also common to disregard how noise in comparisons varies between item pairs, despite it being informative of item similarity. In this work, we study active preference learning for ordering items with contextual attributes, both in- and out-of-sample. We give an upper bound on the expected ordering error of a logistic preference model as a function of which items have been compared. Next, we propose an active learning strategy that samples items to minimize this bound by accounting for aleatoric and epistemic uncertainty in comparisons. We evaluate the resulting algorithm, and a variant aimed at reducing model misspecification, in multiple realistic ordering tasks with comparisons made by human annotators. Our results demonstrate superior sample efficiency and generalization compared to non-contextual ranking approaches and active preference learning baselines.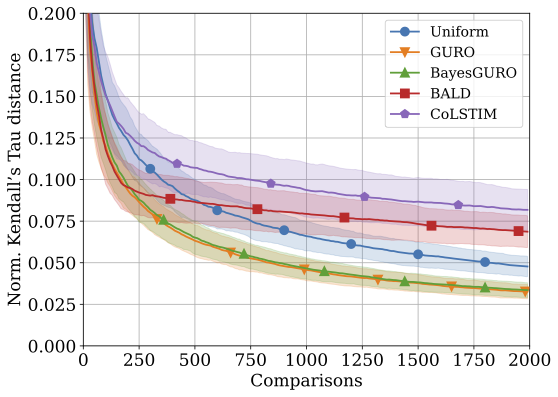
Sep 29, 2024
-
Batched fixed-confidence pure exploration for bandits with switching constraints
ARLET 2024 [Paper URL]Many studies in multi-armed bandits focus on making exploration quick, often obliviously to constraints tied to exploration like the cost of switching between arms. Switching costs arise in many real-world settings like in healthcare when personalizing treatments, where successive assignment of the same treatment could be necessary for treatment to take effect; or in industrial applications where reconfiguring production is costly. Unfortunately, controlling for switching is significantly under-studied outside of regret minimization. In this work, we present a bandit formulation with constraints on the arm switching frequency in fixed-confidence pure exploration and give a lower bound for this setting. We present a batched bandit algorithm called SPB C-Tracking inspired by track-and-stop algorithms, adapted to batch plays with a limited number of arm switches. Finally, we demonstrate empirically that our approach achieves quick stopping times even when constrained to a minimal switching limit.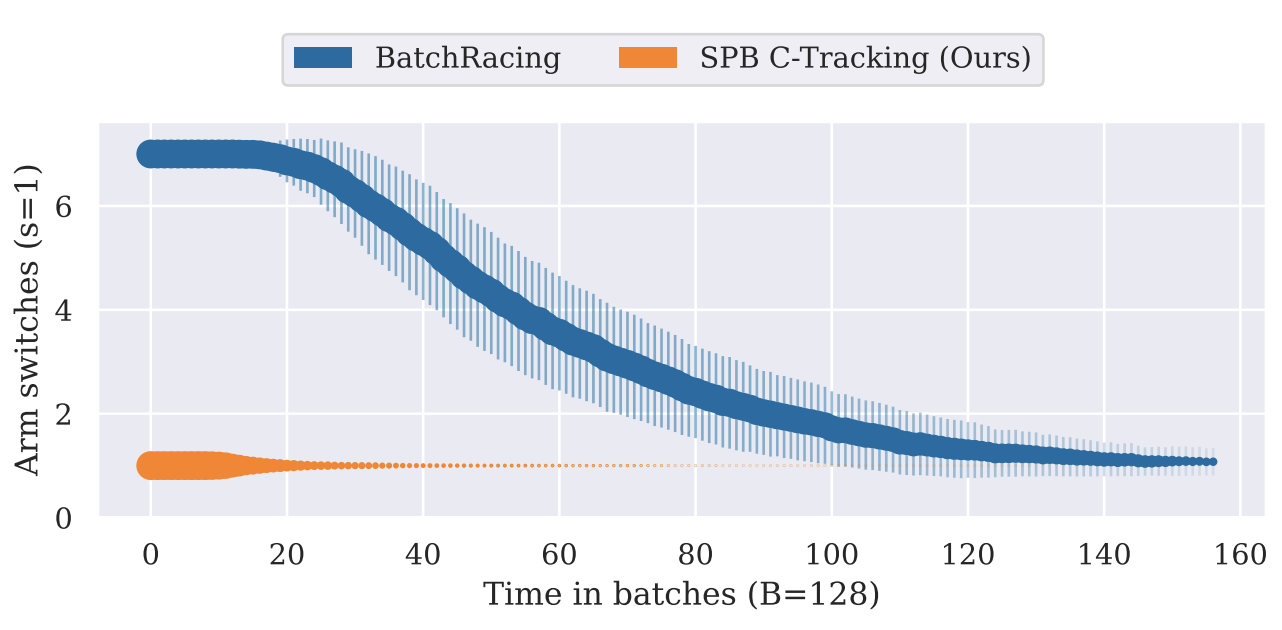
Jul 26, 2024
-
Pure Exploration in Bandits with Linear Constraints
AISTATS 2024 [Paper URL]We address the problem of identifying the optimal policy with a fixed confidence level in a multi-armed bandit setup, when \emph{the arms are subject to linear constraints}. Unlike the standard best-arm identification problem which is well studied, the optimal policy in this case may not be deterministic and could mix between several arms. This changes the geometry of the problem which we characterize via an information-theoretic lower bound. We introduce two asymptotically optimal algorithms for this setting, one based on the Track-and-Stop method and the other based on a game-theoretic approach. Both these algorithms try to track an optimal allocation based on the lower bound and computed by a weighted projection onto the boundary of a normal cone. Finally, we provide empirical results that validate our bounds and visualize how constraints change the hardness of the problem.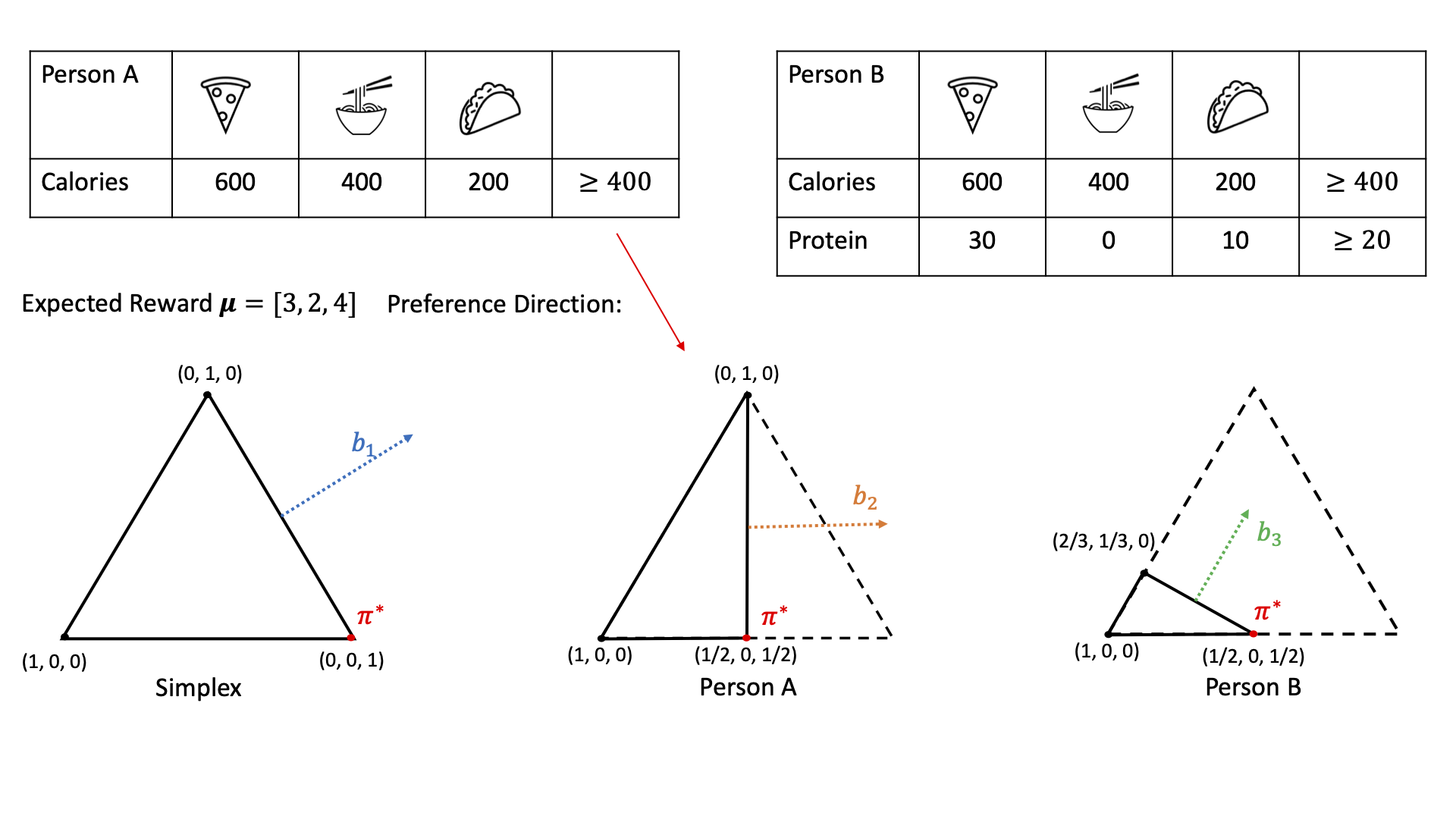
Feb 4, 2024
-
MINTY: Rule-based Models that Minimize the Need for Imputing Features with Missing Values
AISTATS 2024 [Paper URL]Rule models are often preferred in prediction tasks with tabular inputs as they can be easily interpreted using natural language and provide predictive performance on par with more complex models. However, most rule models’ predictions are undefined or ambiguous when some inputs are missing, forcing users to rely on statistical imputation models or heuristics like zero imputation, undermining the interpretability of the models. In this work, we propose fitting concise yet precise rule models that learn to avoid relying on features with missing values and, therefore, limit their reliance on imputation at test time. We develop MINTY, a method that learns rules in the form of disjunctions between variables that act as replacements for each other when one or more is missing. This results in a sparse linear rule model, regularized to have small dependence on features with missing values, that allows a trade-off between goodness of fit, interpretability, and robustness to missing values at test time. We demonstrate the value of MINTY in experiments using synthetic and real-world data sets and find its predictive performance comparable or favorable to baselines, with smaller reliance on features with missing values.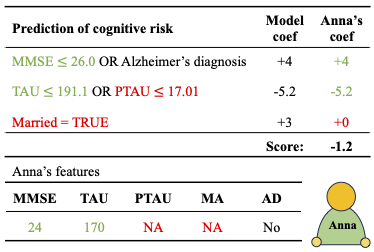
Oct 28, 2023
-
Patterns in the Sequential Treatment of Patients With Rheumatoid Arthritis Starting a Biologic or Targeted Synthetic Disease-Modifying Antirheumatic Drug: 10-Year Experience From a US-Based Registry
ACR [Paper URL]Developing and evaluating new treatment guidelines for rheumatoid arthritis (RA) based on observational data requires a quantitative understanding of patterns in current treatment practice with biologic and targeted synthetic disease-modifying antirheumatic drugs (b/tsDMARDs). We used data from the CorEvitas RA registry to study patients starting their first b/tsDMARD therapy, defined as the first line of therapy, between 2012 and the end of 2021. We identified treatment patterns as unique sequences of therapy changes following and including the first-line therapy. Therapy cycling was defined as switching back to a treatment from a previously used therapeutic class.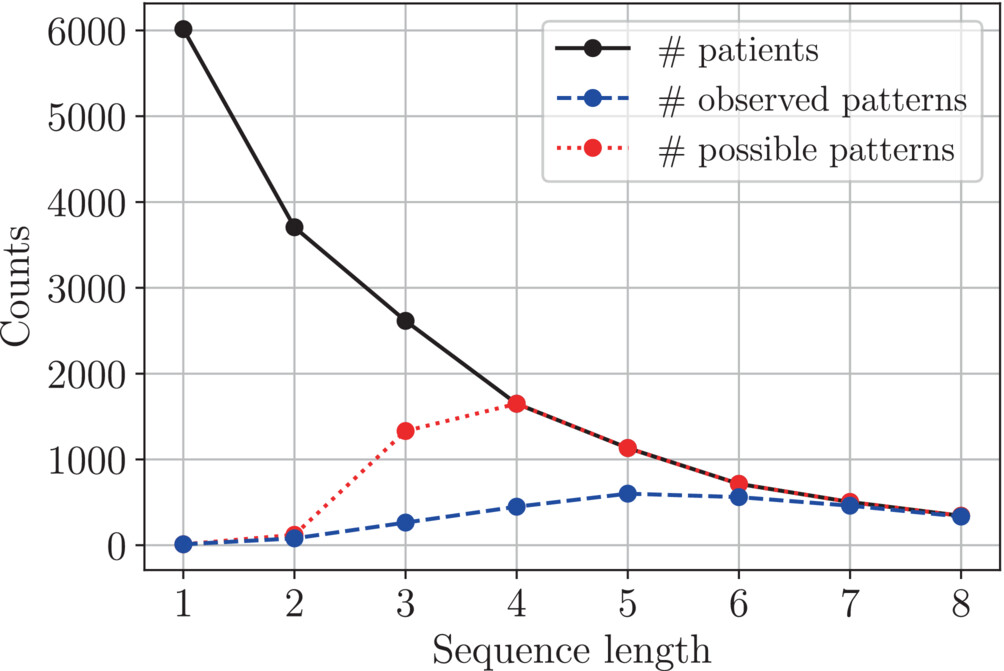
Oct 26, 2023
-
Fast Treatment Personalization with Latent Bandits in Fixed-Confidence Pure Exploration
TMLRPersonalizing treatments for patients often involves a period of trial-and-error search until an optimal choice is found. To minimize suffering and other costs, it is critical to make this process as short as possible. When treatments have primarily short-term effects, search can be performed with multi-armed bandits (MAB), but these typically require long exploration periods to guarantee optimality. In this work, we design MAB algorithms which provably identify optimal treatments quickly by leveraging prior knowledge of the types of decision processes (patients) we can encounter, in the form of a latent variable model. We present two algorithms, the Latent LP-based Track and Stop (LLPT) explorer and the Divergence Explorer for this setting: fixed-confidence pure-exploration latent bandits. We give a lower bound on the stopping time of any algorithm which is correct at a given certainty level, and prove that the expected stopping time of the LLPT Explorer matches the lower bound in the high-certainty limit. Finally, we present results from an experimental study based on realistic simulation data for Alzheimer's disease, demonstrating that our formulation and algorithms lead to a significantly reduced stopping time.May 3, 2023
-
Time series of satellite imagery improve deep learning estimates of neighborhood-level poverty in Africa
IJCAI 2023 - AI for Social GoodTo combat poor health and living conditions, policymakers in Africa require temporally and geographically granular data measuring economic well-being. Machine learning (ML) offers a promising alternative to expensive and time-consuming survey measurements by training models to predict economic conditions from freely available satellite imagery. However, previous efforts have failed to utilize the temporal information available in earth observation (EO) data, which may capture developments important to standards of living. In this work, we develop an EO-ML method for inferring neighborhood-level material-asset wealth using multi-temporal imagery and recurrent convolutional neural networks. Our model outperforms state-of-the-art models in several aspects of generalization, explaining 72% of the variance in wealth across held-out countries and 75% held-out time spans. Using our geographically and temporally aware models, we created spatio-temporal material-asset data maps covering the entire continent of Africa from 1990 to 2019, making our data product the largest dataset of its kind. We showcase these results by analyzing which neighborhoods are likely to escape poverty by the year 2030, which is the deadline for when the Sustainable Development Goals (SDG) are evaluated.Apr 25, 2023
-
Sharing pattern submodels for prediction with missing values
Proceedings of the AAAI Conference on Artificial Intelligence, 37(8), 9882-9890. [Paper URL]Missing values are unavoidable in many applications of machine learning and present a challenge both during training and at test time. When variables are missing in recurring patterns, fitting separate pattern submodels have been proposed as a solution. However, independent models do not make efficient use of all available data. Conversely, fitting a shared model to the full data set typically relies on imputation which may be suboptimal when missingness depends on unobserved factors. We propose an alternative approach, called sharing pattern submodels, which make predictions that are a) robust to missing values at test time, b) maintains or improves the predictive power of pattern submodels, and c) has a short description enabling improved interpretability. We identify cases where sharing is provably optimal, even when missingness itself is predictive and when the prediction target depends on unobserved variables. Classification and regression experiments on synthetic data and two healthcare data sets demonstrate that our models achieve a favorable trade-off between pattern specialization and information sharing.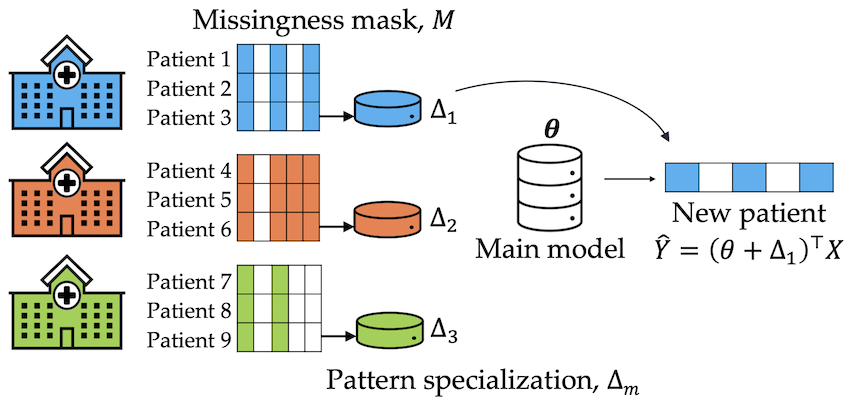
Oct 20, 2022
-
NeurIPS 2022: Efficient learning of nonlinear prediction models with time-series privileged information
NeurIPS 2022 [Paper URL]In domains where sample sizes are limited, efficient learning algorithms are critical. Learning using privileged information (LuPI) offers increased sample efficiency by allowing prediction models access to types of information at training time which is unavailable when the models are used. In recent work, it was shown that for prediction in linear-Gaussian dynamical systems, a LuPI learner with access to intermediate time series data is never worse and often better in expectation than any unbiased classical learner. We provide new insights into this analysis and generalize it to nonlinear prediction tasks in latent dynamical systems, extending theoretical guarantees to the case where the map connecting latent variables and observations is known up to a linear transform. In addition, we propose algorithms based on random features and representation learning for the case when this map is unknown. A suite of empirical results confirm theoretical findings and show the potential of using privileged time-series information in nonlinear prediction.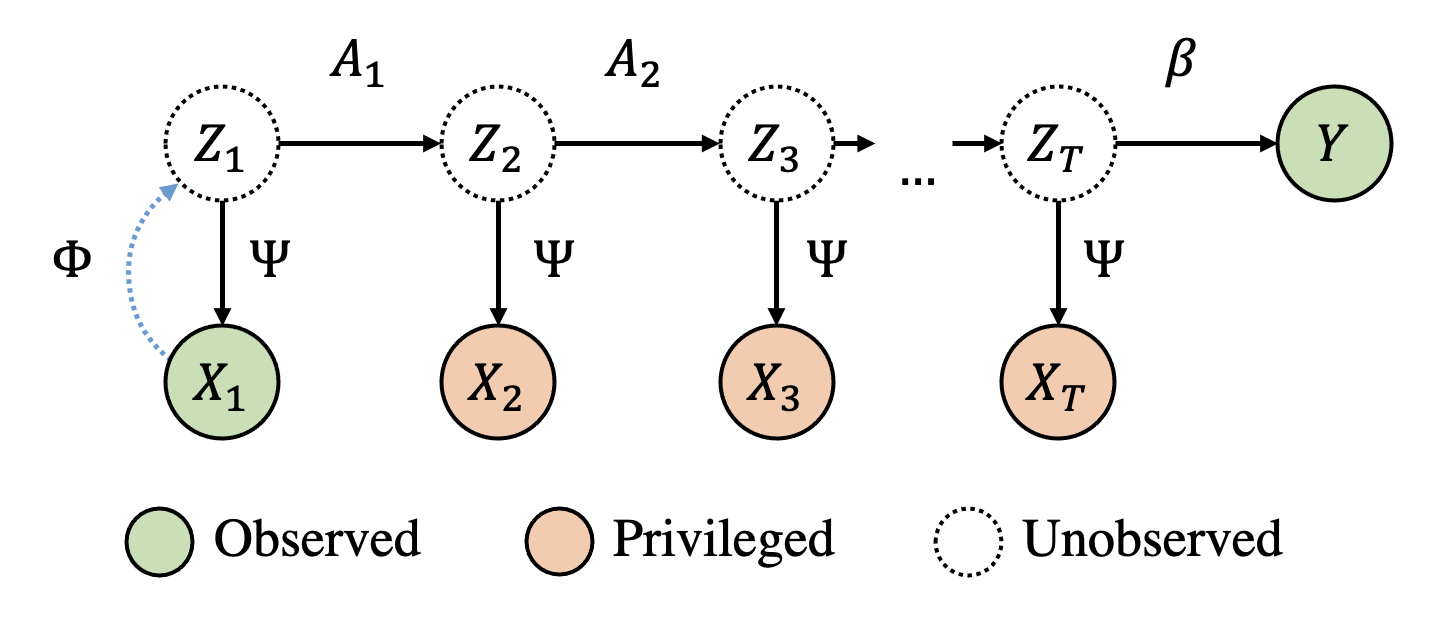
Sep 15, 2022
-
Seminar: Efficient learning of nonlinear prediction models with time-series privileged information
Chalmers machine learning seminarsIn domains where sample sizes are limited, efficient learning is critical. Yet, there are machine learning problems where standard practice routinely leaves substantial information unused. One example is prediction of an outcome at the end of a time series based on variables collected at a baseline time point, for example, the 30-day risk of mortality for a patient upon admission to a hospital. In applications, it is common that intermediate samples, collected between baseline and end points, are discarded, as they are not available as input for prediction when the learned model is used. We say that this information is privileged, as it is available only at training time. In this talk, we show that making use of privileged information from intermediate time series can lead to much more efficient learning. We give conditions under which it is provably preferable to classical learning, and a suite of empirical results to support these findings.
Sep 12, 2022
-
Practicality of generalization guarantees for unsupervised domain adaptation with neural networks
TMLR [Paper URL]Understanding generalization is crucial to confidently engineer and deploy machine learning models, especially when deployment implies a shift in the data domain. For such domain adaptation problems, we seek generalization bounds which are tractably computable and tight. If these desiderata can be reached, the bounds can serve as guarantees for adequate performance in deployment. However, in applications where deep neural networks are the models of choice, deriving results which fulfill these remains an unresolved challenge; most existing bounds are either vacuous or has non-estimable terms, even in favorable conditions. In this work, we evaluate existing bounds from the literature with potential to satisfy our desiderata on domain adaptation image classification tasks, where deep neural networks are preferred. We find that all bounds are vacuous and that sample generalization terms account for much of the observed looseness, especially when these terms interact with measures of domain shift. To overcome this and arrive at the tightest possible results, we combine each bound with recent data-dependent PAC-Bayes analysis, greatly improving the guarantees. We find that, when domain overlap can be assumed, a simple importance weighting extension of previous work provides the tightest estimable bound. Finally, we study which terms dominate the bounds and identify possible directions for further improvement.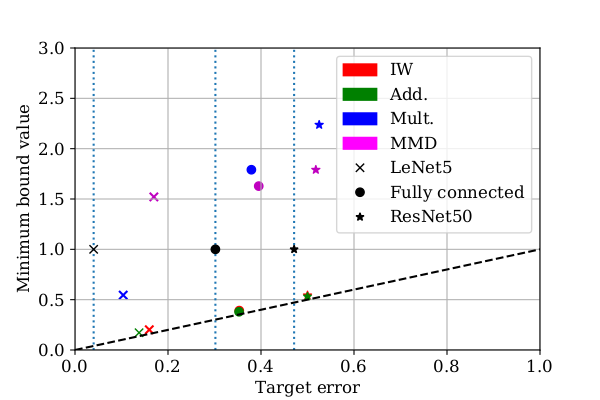
Sep 2, 2022
-
Case-Based Off-Policy Evaluation Using Prototype Learning
UAI 2022 [Paper URL]Importance sampling (IS) is often used to perform off-policy evaluation but it is prone to several issues---especially when the behavior policy is unknown and must be estimated from data. Significant differences between target and behavior policies can result in uncertain value estimates due to, for example, high variance. Standard practices such as inspecting IS weights may be insufficient to diagnose such problems and determine for which type of inputs the policies differ in suggested actions and resulting values. To address this, we propose estimating the behavior policy for IS using prototype learning. The learned prototypes provide a condensed summary of the input-action space, which allows for describing differences between policies and assessing the support for evaluating a certain target policy. In addition, we can describe a value estimate in terms of prototypes to understand which parts of the target policy have the most impact on the estimate. We find that this provides new insights in the examination of a learned policy for sepsis management. Moreover, we study the bias resulting from restricting models to use prototypes, how bias propagates to IS weights and estimated values and how this varies with history length.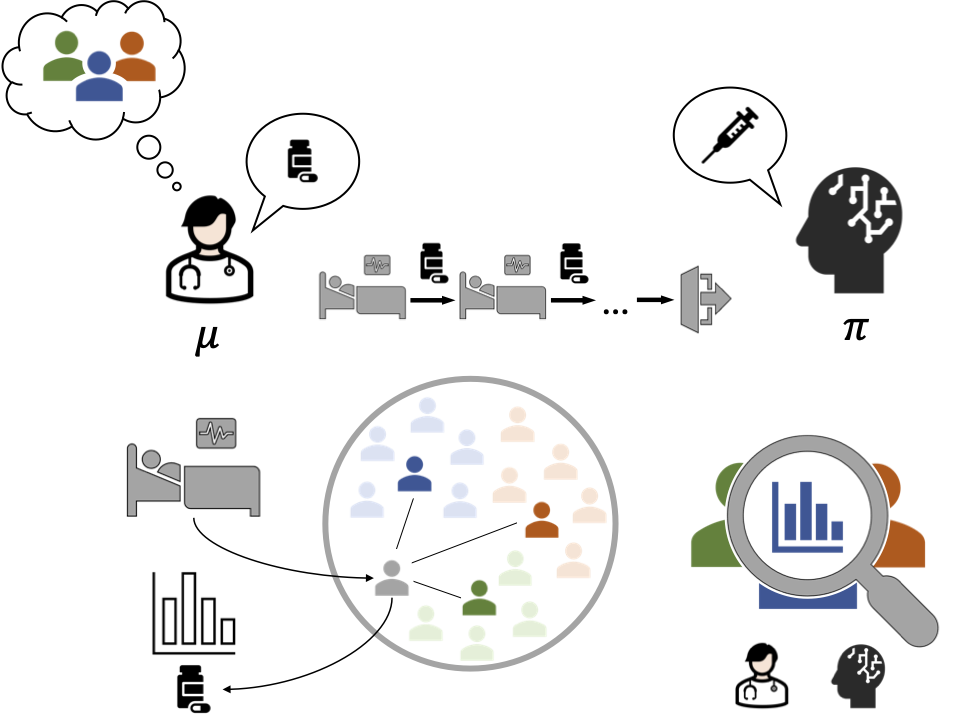
Jul 27, 2022
-
ADCB: An Alzheimer’s disease simulator for benchmarking observational estimators of causal effects
CHIL 2022 [Paper URL]Simulators make unique benchmarks for causal effect estimation as they do not rely on unverifiable assumptions or the ability to intervene on real-world systems. This is especially important for estimators targeting healthcare applications as possibilities for experimentation are limited with good reason. We develop a simulator of clinical variables associated with Alzheimer’s disease, aimed to serve as a benchmark for causal effect estimation while modeling intricacies of healthcare data. We fit the system to the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset and ground hand-crafted components in results from comparative treatment trials and observational treatment patterns. The simulator includes parameters which alter the nature and difficulty of the causal inference tasks, such as latent variables, effect heterogeneity, length of observed subject history, behavior policy and sample size. We use the simulator to compare standard estimators of average and conditional treatment effects.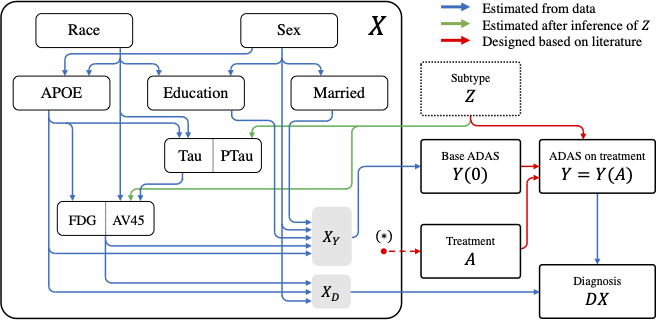
Apr 7, 2022
-
Learning using privileged time series information
AISTATS 2022 [Paper URL]We study prediction of future outcomes with supervised models that use privileged information during learning. The privileged information comprises samples of time series observed between the baseline time of prediction and the future outcome; this information is only available at training time which differs from the traditional supervised learning. Our question is when using this privileged data leads to more sample-efficient learning of models that use only baseline data for predictions at test time. We give an algorithm for this setting and prove that when the time series are drawn from a non-stationary Gaussian-linear dynamical system of fixed horizon, learning with privileged information is more efficient than learning without it. On synthetic data, we test the limits of our algorithm and theory, both when our assumptions hold and when they are violated. On three diverse real-world datasets, we show that our approach is generally preferable to classical learning, particularly when data is scarce. Finally, we relate our estimator to a distillation approach both theoretically and empirically.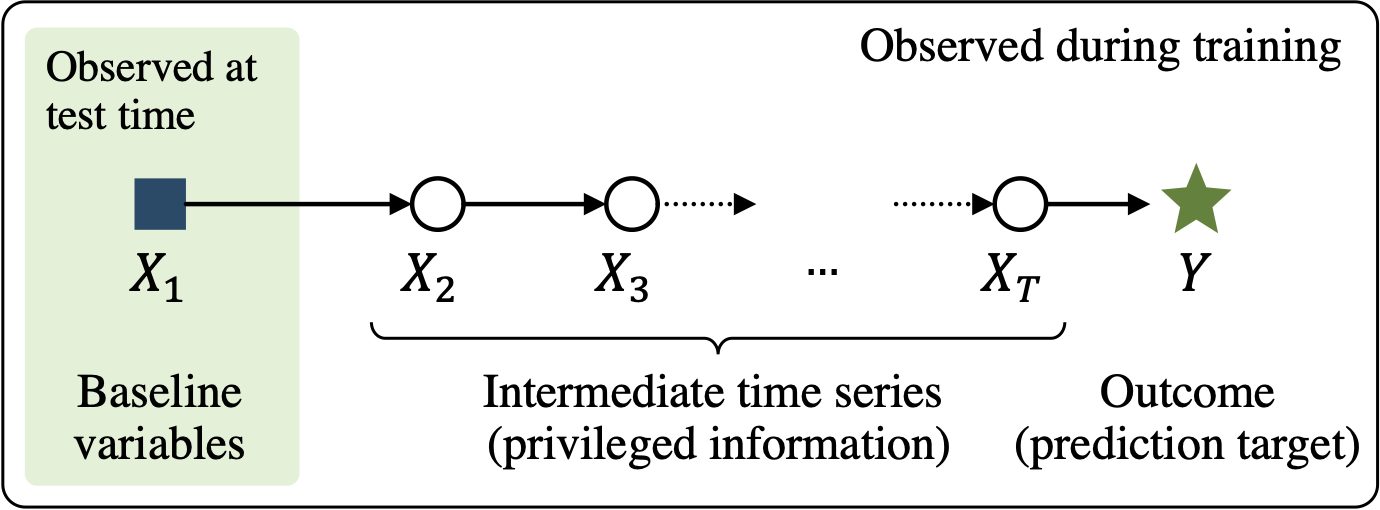
Feb 1, 2022
-
Predicting progression & cognitive decline in amyloid-positive patients with Alzheimer's disease
Alzheimer's Research & Therapy [Paper URL]In Alzheimer’s disease, amyloid-β (Aβ) peptides aggregate in the brain forming CSF amyloid levels, which are a key pathological hallmark of the disease. However, CSF amyloid levels may also be present in cognitively unimpaired elderly individuals. Therefore, it is of great value to explain the variance in disease progression among patients with Aβ pathology. We studied the problem of predicting disease progression and cognitive decline of potential AD patients with established Aβ pathology using the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database.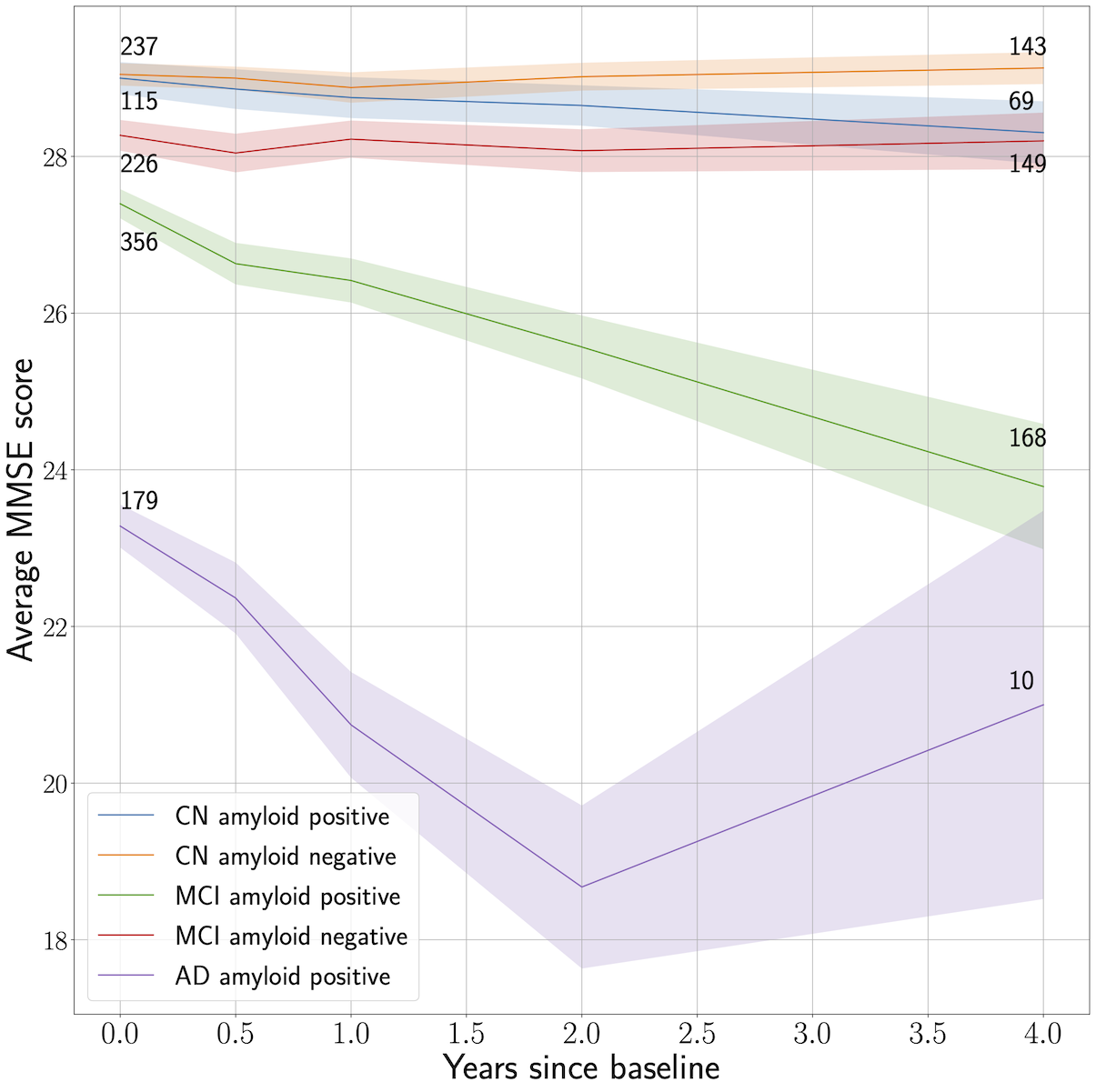
Mar 15, 2021
-
Tocilizumab treatment for rheumatoid arthritis
As of September 2020, the division of Data Science & AI have four brand new PhD students with Fredrik Johansson as main advisor. This marks the start of the Healthy AI lab at Chalmers University of Technology. Adam Breitholtz, Newton Mwai, Lena Stempfle and Anton Matsson begin their doctoral studies, funded by the Wallenberg AI, Autonomous Systems and Software programme.Feb 1, 2021
-
Learning to search efficiently for causally near-optimal treatments
NeurIPS 2020 [Paper URL]Finding an effective medical treatment often requires a search by trial and error. Making this search more efficient by minimizing the number of unnecessary trials could lower both costs and patient suffering. We formalize this problem as learning a policy for finding a near-optimal treatment in a minimum number of trials using a causal inference framework. We give a model-based dynamic programming algorithm which learns from observational data while being robust to unmeasured confounding. To reduce time complexity, we suggest a greedy algorithm which bounds the near-optimality constraint. The methods are evaluated on synthetic and real-world healthcare data and compared to model-free reinforcement learning. We find that our methods compare favorably to the model-free baseline while offering a more transparent trade-off between search time and treatment efficacy.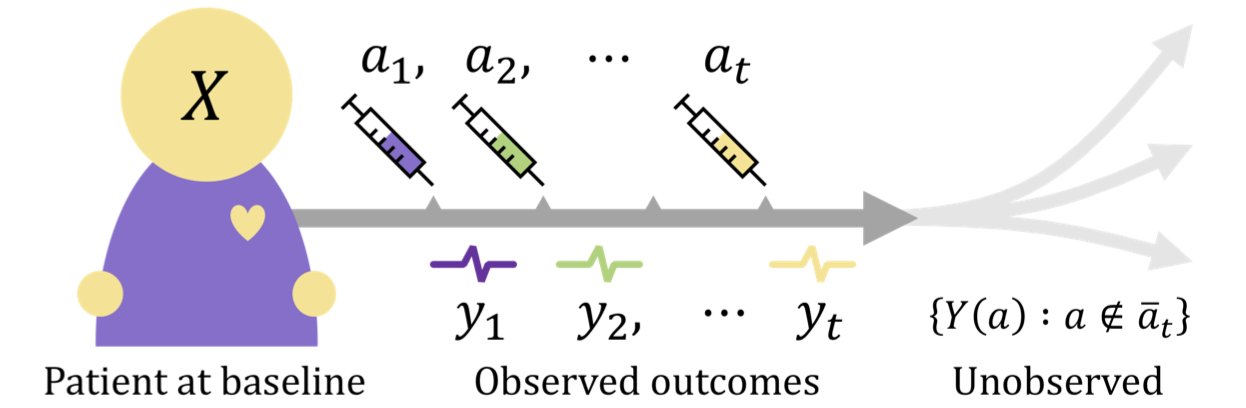
Dec 31, 2020
-
A new group: The Healthy AI lab!
As of September 2020, the division of Data Science & AI have four brand new PhD students with Fredrik Johansson as main advisor. This marks the start of the Healthy AI lab at Chalmers University of Technology. Adam Breitholtz, Newton Mwai, Lena Stempfle and Anton Matsson begin their doctoral studies, funded by the Wallenberg AI, Autonomous Systems and Software programme.Sep 1, 2020