Case-Based Off-Policy Evaluation Using Prototype Learning
UAI 2022 [Paper URL]
Estimating the behavior policy for off-policy evaluation using prototypes allows us to describe differences between policies and their estimated values
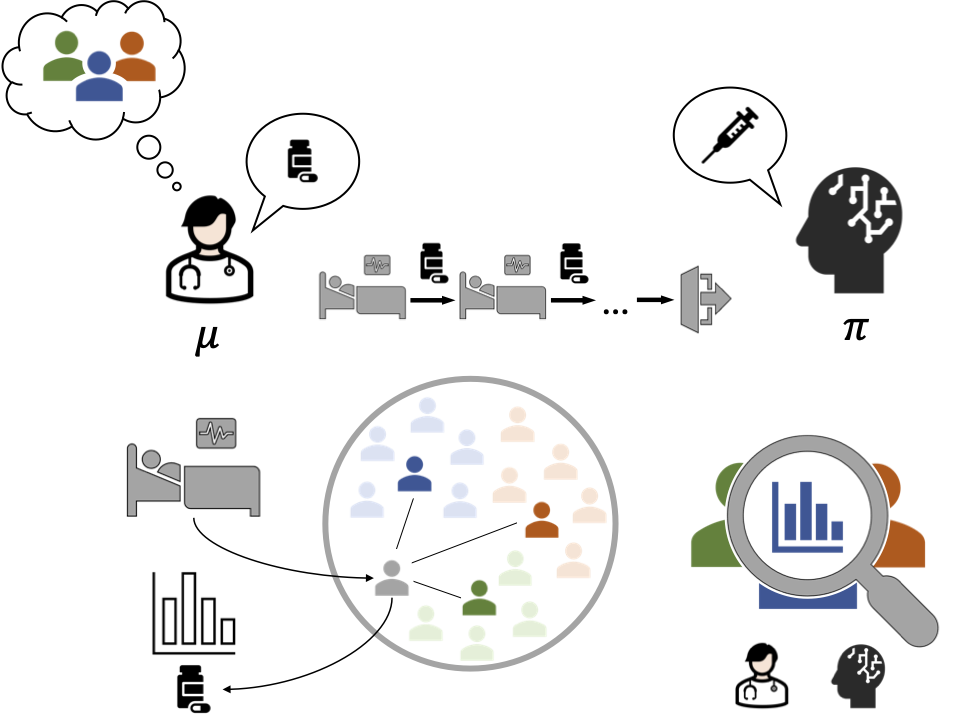
The increasing amount of available data on medical interventions and reported outcomes creates opportunities to search for new clinical policies. As an example, researchers have employed reinforcement learning algorithms to learn new strategies for the management of sepsis [1]. However, for such a policy to be used in practice, it is of utmost importance that its performance, or value, can be reliably estimated. Ideally, the estimated value of this target policy should be higher than the value of the—often unknown—behavior policy followed by clinicians in the observed data.
While the value of the behavior policy can be easily estimated by averaging outcomes in the observed data, the value of the target policy is fundamentally unknown. Off-policy evaluation (OPE) refers to the problem of estimating the target policy value using data collected under the behavior policy. A standard method for OPE is importance sampling (IS), where each observed outcome is weighted by the probability ratio of taking the actions preceding that outcome under the target policy and the behavior policy, respectively. When the behavior policy is unknown, it must be estimated from data before the IS average can be computed.
Even though importance sampling is a popular method for OPE, it suffers from high variance when there are significant differences between target and behavior policies. By inspecting the IS weights, it is possible to collect individual samples for which the policies differ, but this approach does not describe patterns in differences between polices. To address this problem, we suggest estimating the unknown behavior policy using prototype learning [2], which gives us a set of interpretable prototype cases from the observed data. The prototypes are selected by the learning algorithm, and for a specific input, e.g., a patient, the model estimates the behavior policy by comparing the input to the prototypes in a learned representation. The idea is reminiscent of how physicians use their experience from previous patients when treating new ones.
We use the learned prototypes as a diagnostic tool for OPE. By inspecting the behavior and target policies for each of the prototypes, we obtain a condensed overview of differences between the policies. A domain expert can reason about the validity of the target policy and assess whether the data supports evaluating it using importance sampling. Additionally, we use the prototypes to divide estimated policy values into prototype-based components, allowing us to describe situations when it may be beneficial to follow the target policy instead of the behavior policy, and vice versa.
If you are interested, you are welcome to read our UAI 2022 paper [3], where we elaborate on the prototype idea and demonstrate it using a real-world example of sepsis management.
- [1] Matthieu Komorowski et al. The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nature Medicine, 24(11): 1716–1720, 2018.
- [2] Yao Ming et al. Interpretable and steerable sequence learning via prototypes. In The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019.
- [3] Anton Matsson and Fredrik Johansson. Case-based off-policy evaluation using prototype learning. In The 38th Conference on Uncertainty in Artificial Intelligence, 2022.