Sharing pattern submodels for prediction with missing values
Proceedings of the AAAI Conference on Artificial Intelligence, 37(8), 9882-9890. [Paper URL]
Abstract
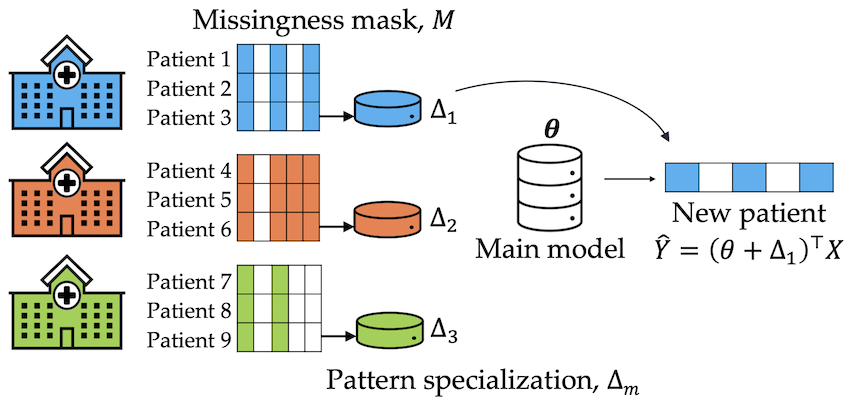
Missing values are unavoidable in many applications of machine learning and present a challenge both during training and at test time. When variables are missing in recurring patterns, fitting separate pattern submodels have been proposed as a solution. However, independent models do not make efficient use of all available data. Conversely, fitting a shared model to the full data set typically relies on imputation which may be suboptimal when missingness depends on unobserved factors. We propose an alternative approach, called sharing pattern submodels, which make predictions that are a) robust to missing values at test time, b) maintains or improves the predictive power of pattern submodels, and c) has a short description enabling improved interpretability. We identify cases where sharing is provably optimal, even when missingness itself is predictive and when the prediction target depends on unobserved variables. Classification and regression experiments on synthetic data and two healthcare data sets demonstrate that our models achieve a favorable trade-off between pattern specialization and information sharing.